Set up a Content Source with API
SearchUnify supports more than 30 content sources out-of-the-box. Any data repository that is not in the list can be transformed into a content source with APIs. It's secure because API is OAuth 1.0 compliant. This article walks you through the process.
Prerequisites
- Content source with a working API and structured data
- Familiarity with essential REST API terminology
Establish a Connection
- Navigate to Content Sources.
- Click Add new content source.


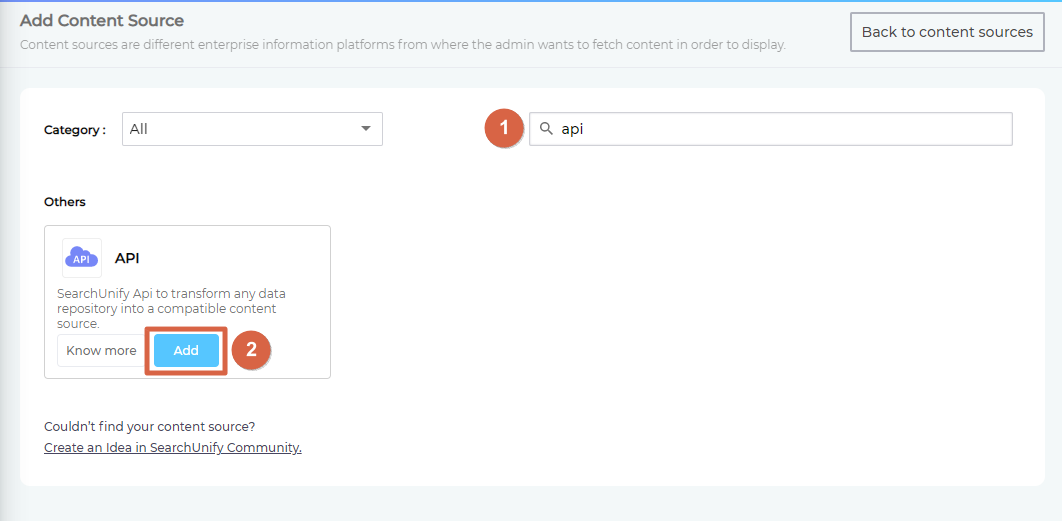
- Find the content source through the search box and click Add.
- Give your content source a Name.

- In the Client URL field, enter the base URL of your API. It might resemble
https://mycompany.platform.com/api/v2.
- Click Connect.





Configure the Calls
This section covers setting up a process to crawl and index your content through APIs.
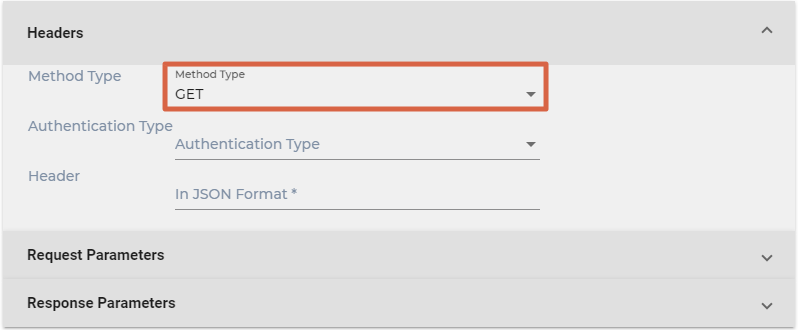
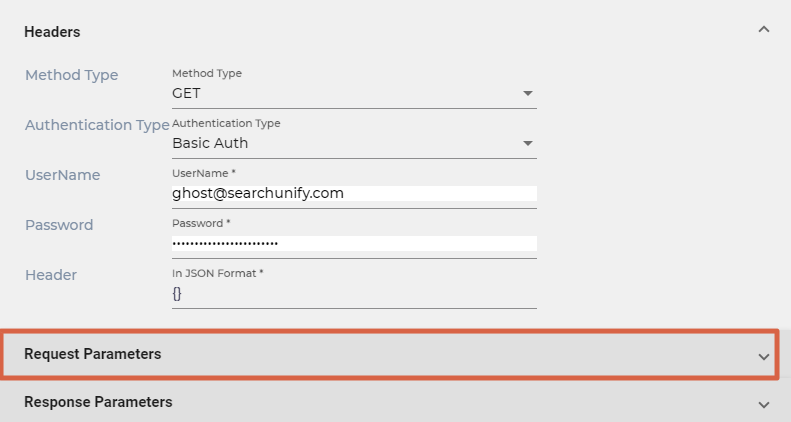
- Select either GET or POST from Method Type.
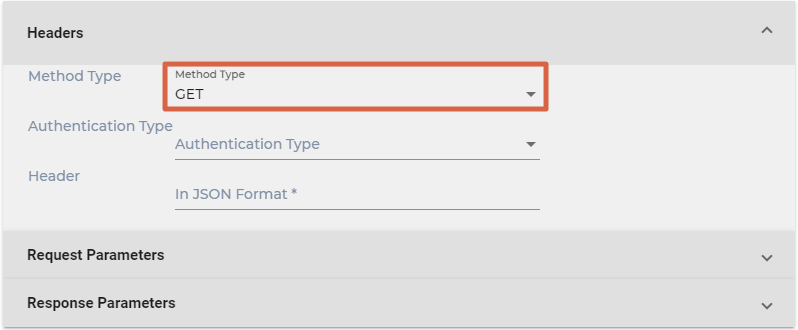
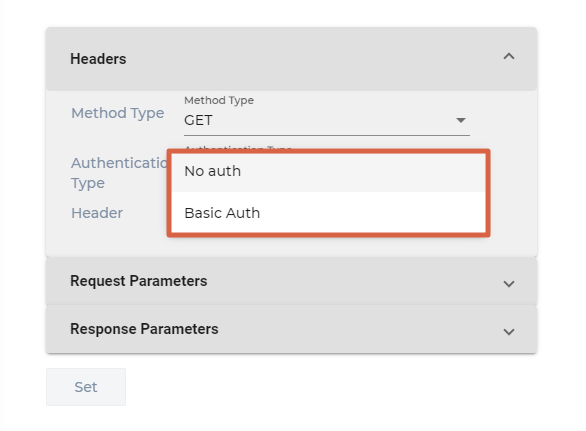
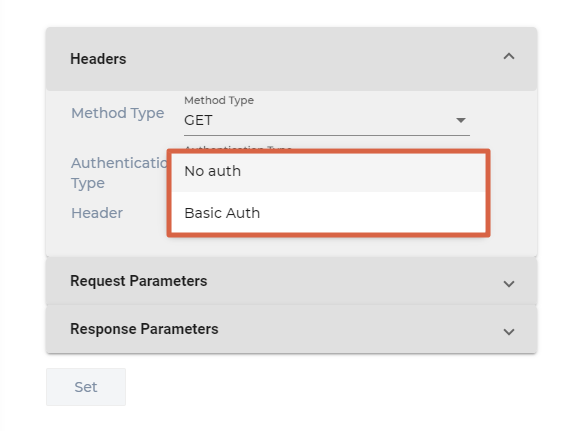
- Select an Authentication Type. You can pick:
- No Auth. No changes are needed.
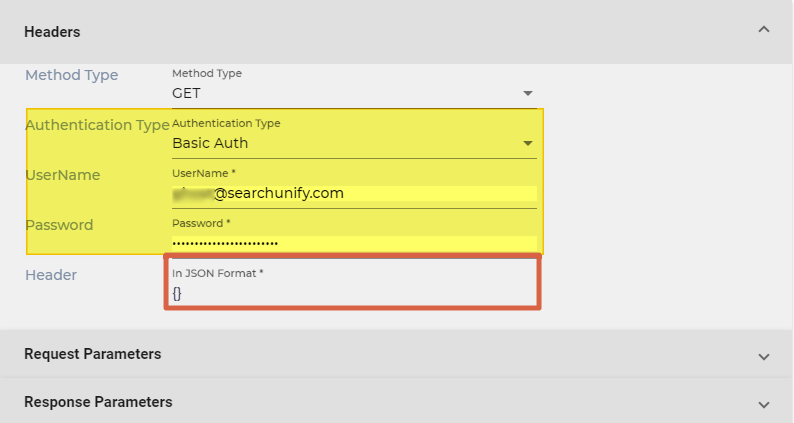
- Basic Auth. Enter the user name and password required to make calls to your REST API.
- Write all the key-value pairs to be used in Header in the format JSON. If you want to keep the field empty, write a pair of curly braces ({}).
- Open Request Parameters.
- Enter query parameters needed to consume your REST API. The format of the parameters will be JSON.
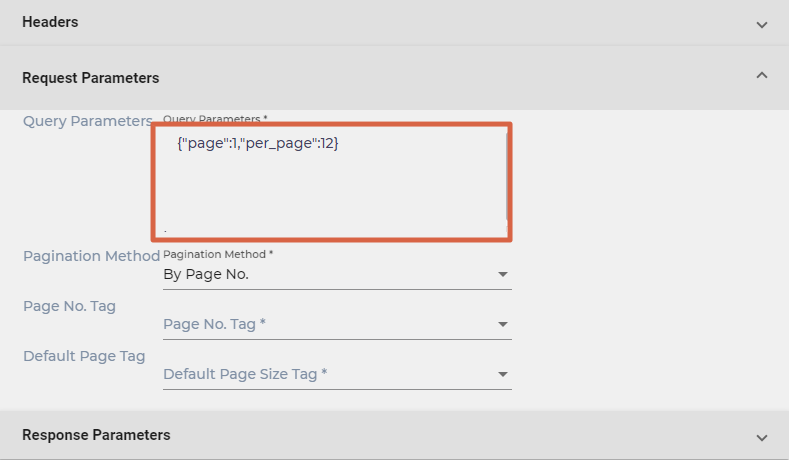
- Select a pagination method:
- By Page No. Almost no platform returns data in a single go. That means a caller will have to make multiple calls to get all the documents and each call will be slightly different. The difference is usually a field in your query parameter which has to be selected in the Page No. Tag dropdown. Page No. Tag appears when you select By Page No. as your pagination method. It gets incremented with each call and fetches a new batch of documents each time it is run. Default Page Tag—which also appears when you select By Page No.—determines the size of each page. If the value of its parameter is 10, then there will be 10 results on each page.
- By Start Offset. It is similar to By Page No. The only difference being that the variable used to differentiate calls is Page Start Offset Tag.
- By Next Link. It is an object with two key-pair values: a Boolean and a link. The crawler uses the value stored in the link as the differentiating variable as long as the Boolean is
true. - No Pagination. The entire data is indexed in one go. It is extremely rare to encounter a content source that will accept this method.

- Open Response Parameters.

- Enter a JSON snippet that contains all the response parameters.
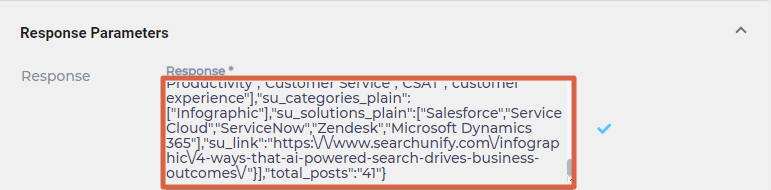
- Select a Result Iteration Tag and an Index Tag. Result Iteration Tag is a response field that contains the data you wish to index. Index Tag contains a unique ID to distinguish document from one another.

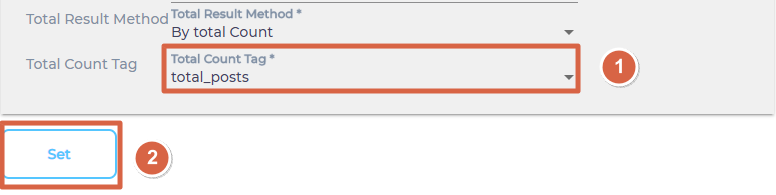
- SearchUnify will stop making calls to your content source once all your documents have been indexed. Total Results Method keeps a count of the total and indexed documents and there are two ways to keep this count: By Total Count or By Has More Flag. Select one.

- From Total Count Tag, select a parameter returns total count and click Set.








Set Up Crawl Frequency
- Click
 to fire up a calendar and select a date.
to fire up a calendar and select a date. 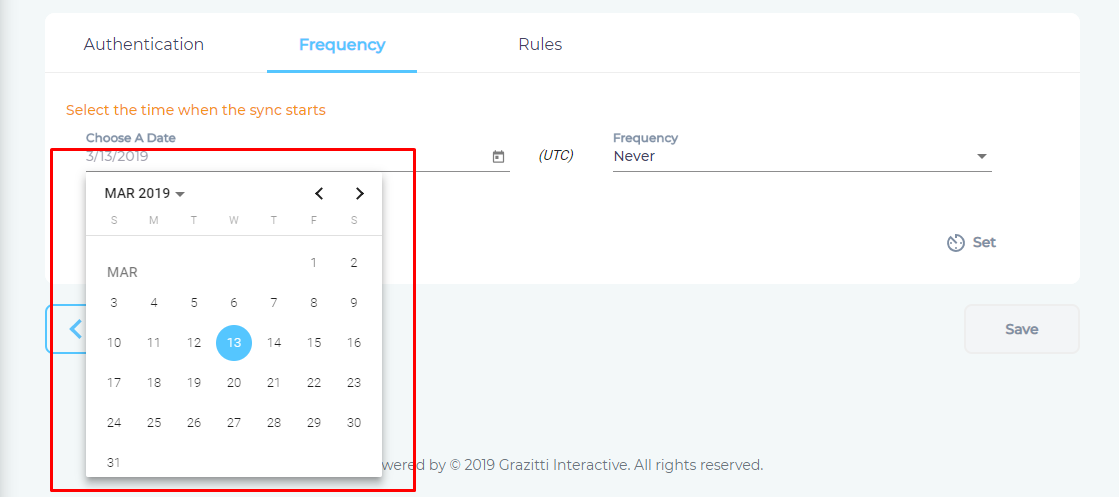
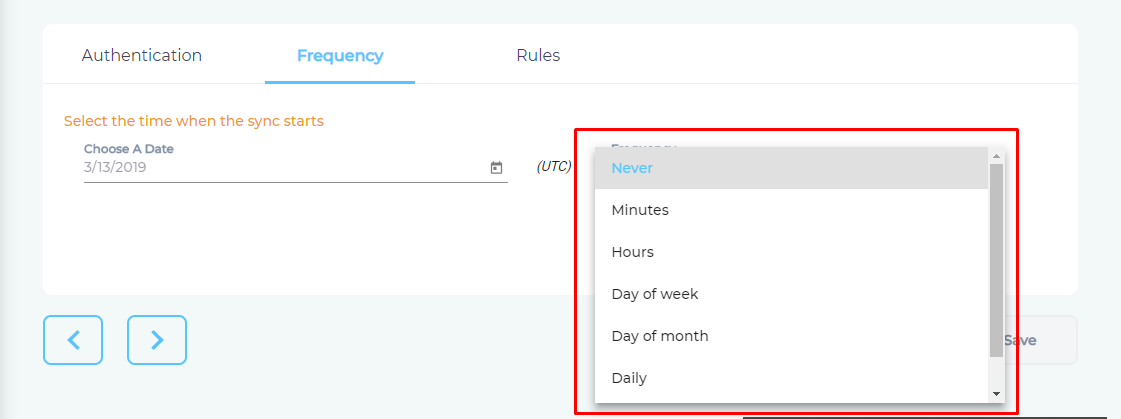
- Use the Frequency dropdown to select how often SearchUnify should index the data.
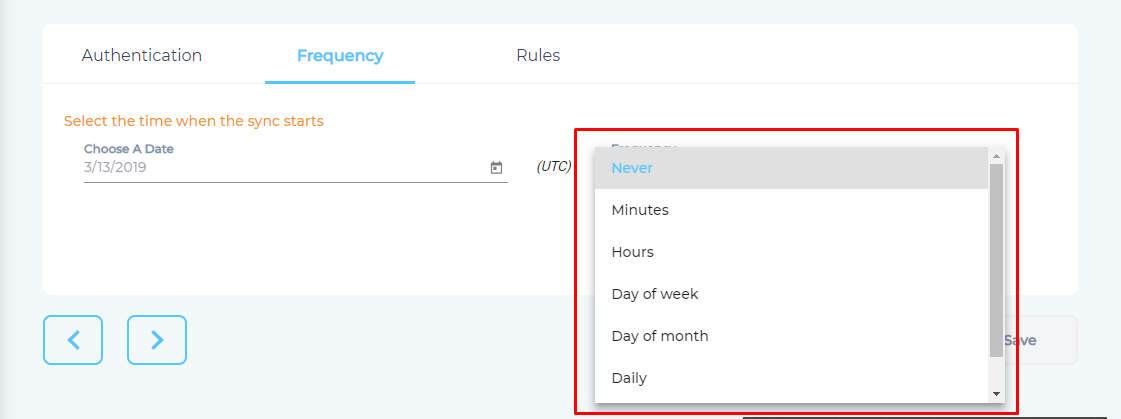
- Click Set.



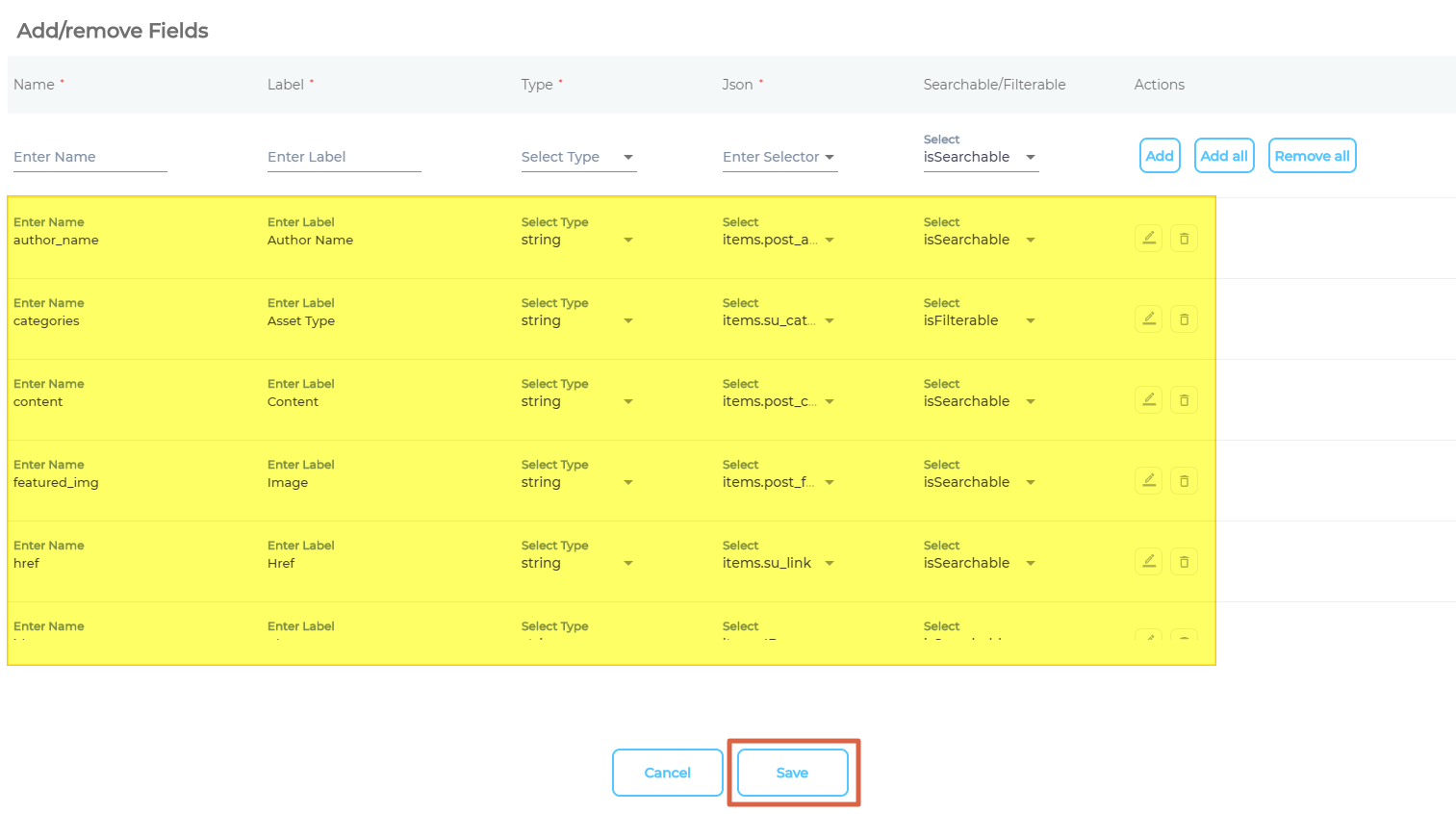
Add the Objects and Fields for Indexing
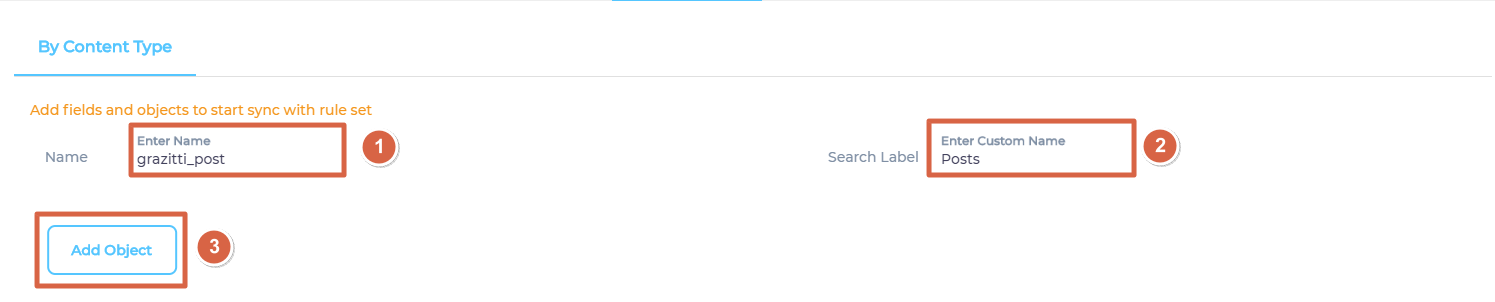
- Enter an object where your data is stored, give it a label, and click Add Object.
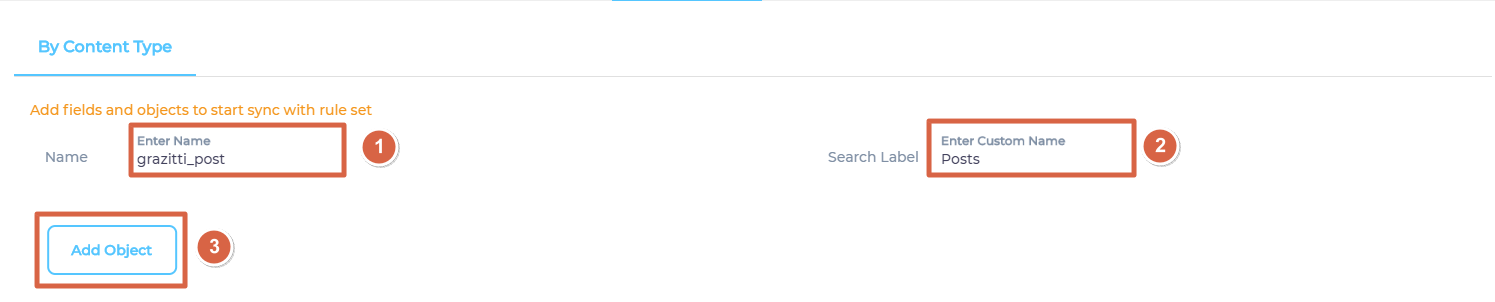
- Repeat the previous step if you wish to add more than one object.
- Click
 to manage fields.
to manage fields.

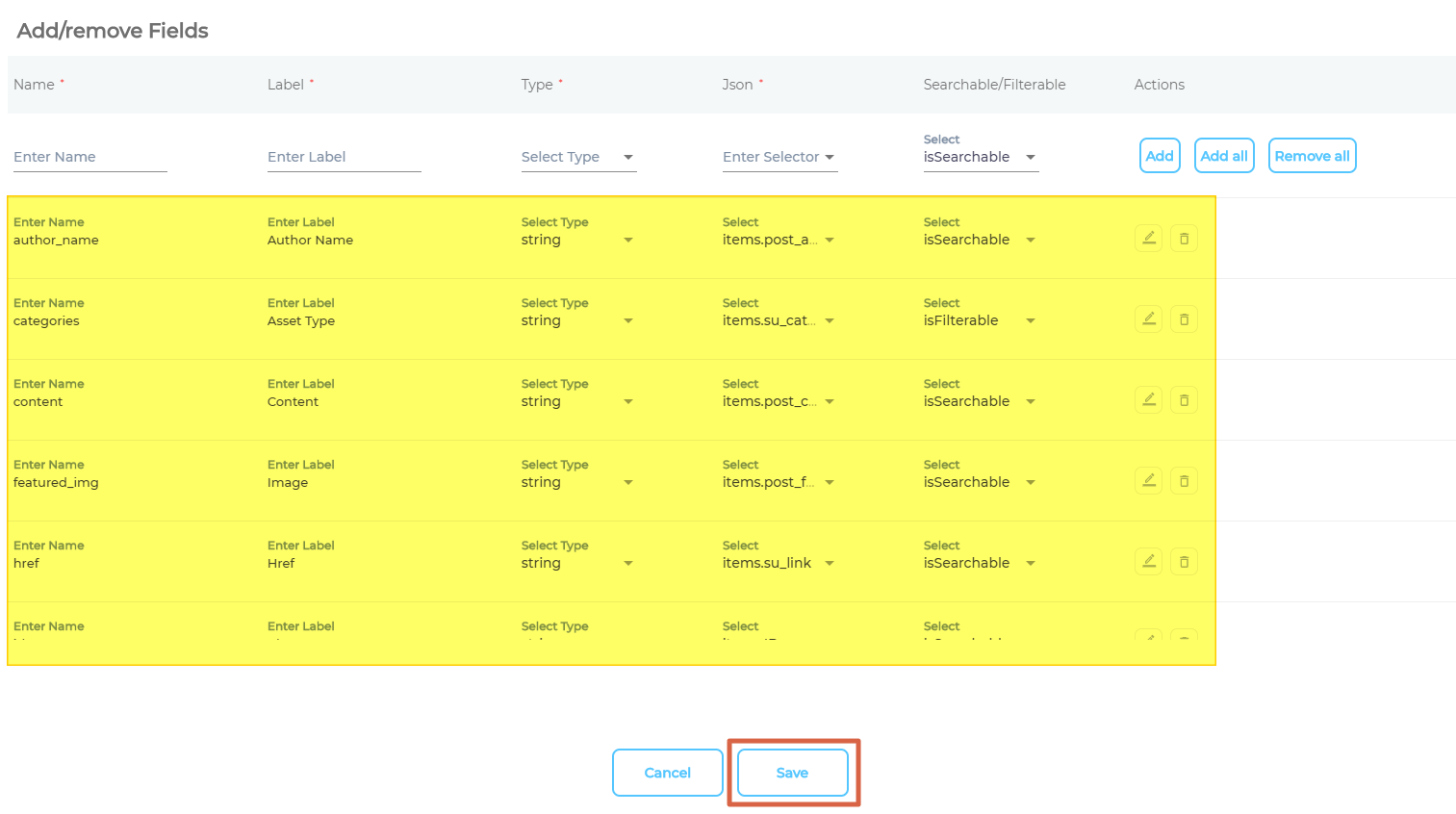
- Add all the fields that you wish to index and click Save.
- Click Save.

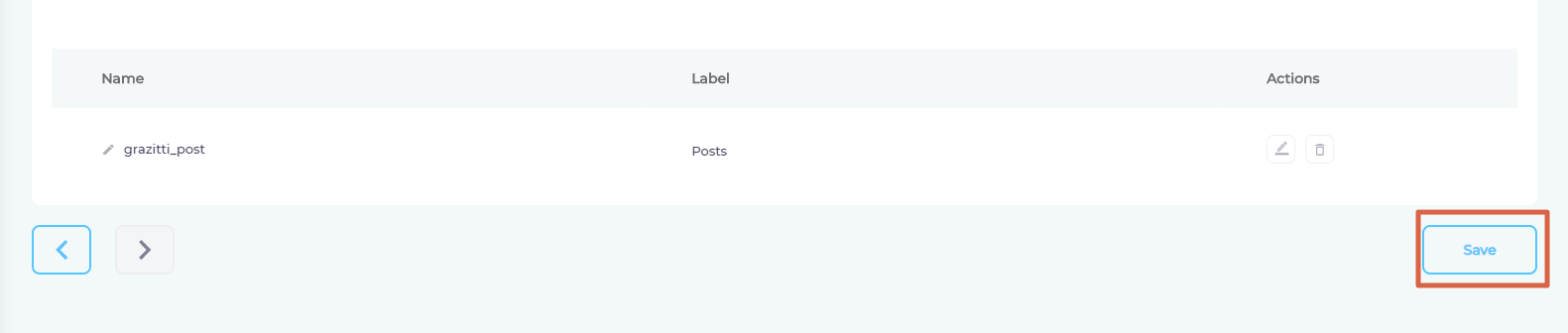
If you selected Never in Set Up Crawl Frequency, then go to the Content Sources screen and click ![]() .
.

Last updated: Friday, February 26, 2021
Was this article helpful? Send us your review at help-feedback@searchunify.com