

Crawl an Object in Salesforce
The data stored in a Salesforce instance can be huge, which makes it time-consuming and computationally-intensive to crawl the entire org’s data while the updates are limited to just one object.
Salesforce Object Crawl solves this problem. It allows SearchUnify admins to crawl Salesforce objects one at a time. A big advantage of object crawl is that it's faster and safer.
-
Crawling an object takes less time than crawling an entire org.
-
When an object crawl fails, the overall index isn't impacted. Instead of adding new fields into the main index, you can try adding new objects instead.
Crawl an Object
-
Open the Salesforce content source for editing. Go to the Rules tab.
-
Click
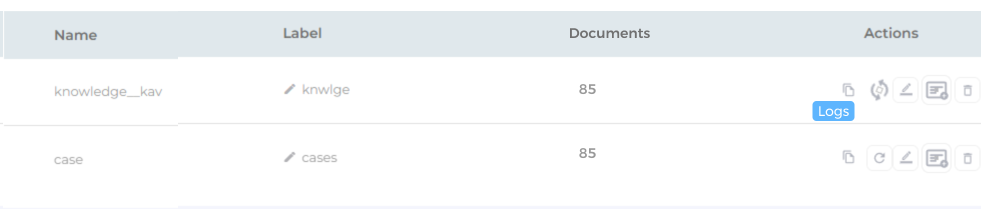
 (Crawl/Update Object) to crawl the data in an object. In the image, data from the "case" object will be crawled.
(Crawl/Update Object) to crawl the data in an object. In the image, data from the "case" object will be crawled.
-
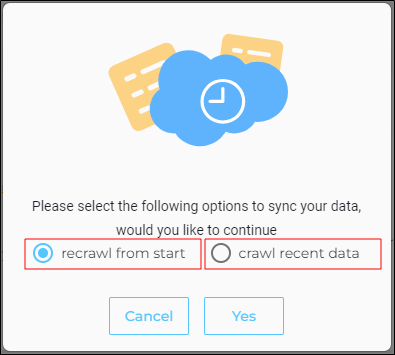
Select one of the object crawl types:
-
Recrawl from start deletes the entire index for the object. All the data in the object is crawled from the start date mentioned in the Frequency tab. Then, a new index is created.
-
Crawl recent data crawls the data from the last synchronized date. If the last crawl was a month ago, then only the data added in the past month is added to the index. The older records remain in the index.
- While the object is being crawled, the status can be viewed from Crawl Logs.
Once the object has been crawled, the total number of documents indexed from that particular object is displayed in the Documents column.

{kind=link}
Fig. Snapshot of the document count after object crawl.
If fields have been added or removed from an object, then instead of “Crawl/Update Object”, a longer message will be displayed “This object has been updated. Please crawl it to update the index as well.”

Fig. Snapshot of the message when fields have been added or removed from an object.