

Use Confluence As a Content Source
SearchUnify can index the pages and blogs stored in your Confluence instance. This article walks you through the process of setting up Confluence as a content source.
PERMISSIONS
SearchUnify applies Space and Page permissions.
Admins can only crawl the Spaces and Pages for which they have view access.
Users can only find documents in the Spaces and Pages for which they have view access.
The Page permissions take precedence between the Space and Page permissions.
If an admin has access to a Space and a user has hidden a few Pages in that particular Space, then the admin can crawl all the pages in that Space except the hidden Pages.
Users cannot find the hidden Pages in search results even if they have access to that Space.
Nested permissions are supported up to eight levels.
The number of responses received from Confluence over a given period depend upon the Confluence's rate limits. You can find the the latest rate limits on their website.
Establish a Connection
-
Navigate to Content Sources and click Add New Content Sources.
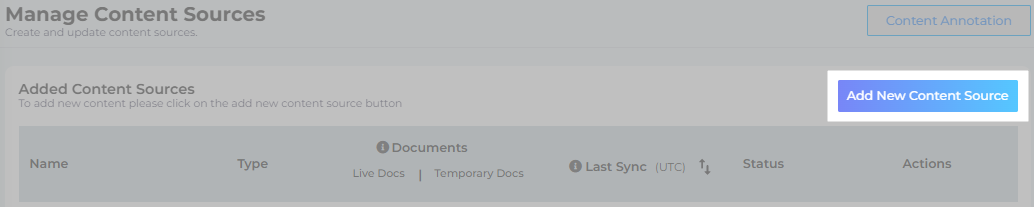
- Find "Confluence" through the search box and click Add.
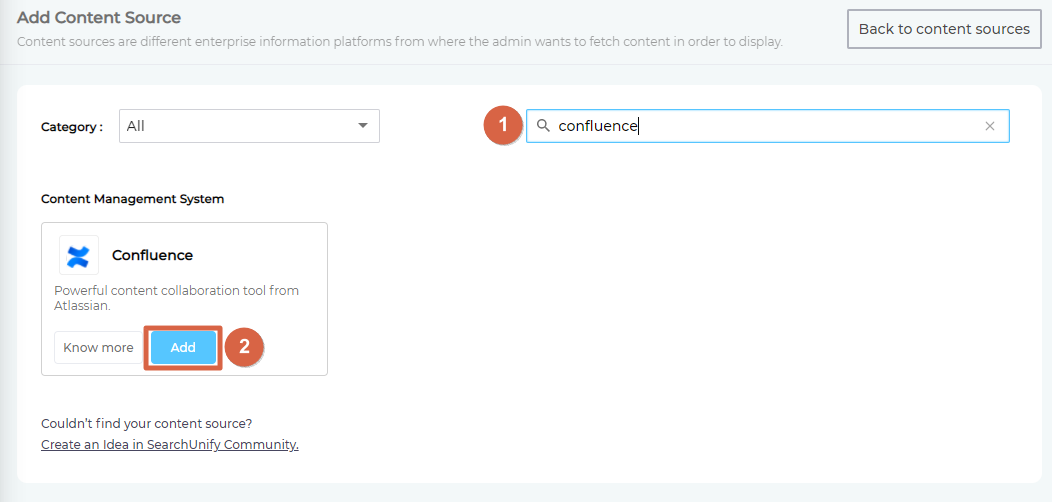
- Give your content source a name.

- Enter the web address of your Confluence instance followed by wiki/ in Client URL.
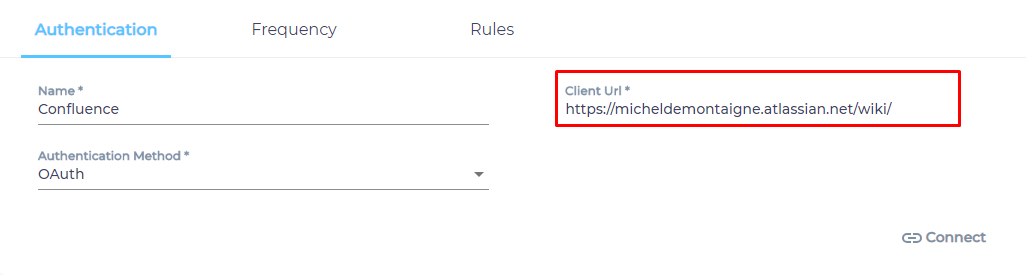
- Select an Authentication Method.
- Basic. Select it to crawl the spaces that the Confluence user, whose username and API token has been entered, is allowed to access. Anybody who is part of an organization can authenticate and crawl data. Every user will need to create their own API token. Check out SearchUnify's doc on Create an API Token in Atlassian (Jira and Confluence) or the Confluence doc on Create an API Token.
- OAuth. Select it to crawl all the spaces and projects to which the client application has access. The level of access and permissions granted to the client application depends on the admin's role and the permissions assigned to them in Confluence. Only a Confluence admin can create the client application. The instructions are in Create an App in Confluence (from SearchUnify) and in Conflgure an Incoming Link (from Confluence).
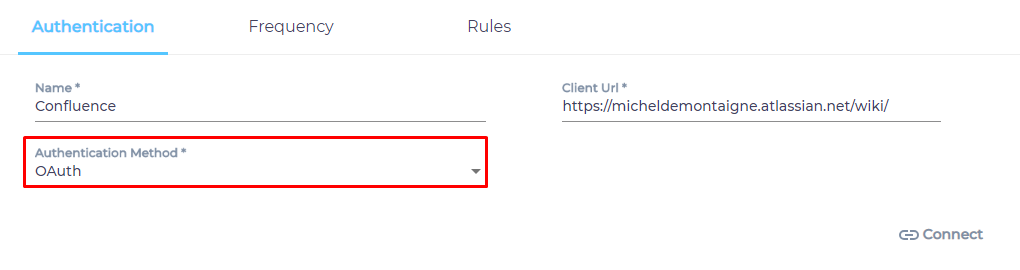
- Click Connect.
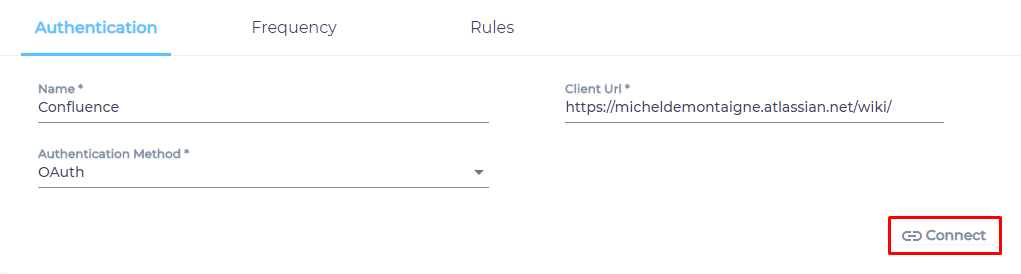
Re-Connect
An admin can edit a Content Source for multiple reasons, including:
-
To reauthenticate
-
To fix a crawl error
-
To change frequency
-
To add or remove an object or a field for crawling
When a Content Source is edited, either a Connect or a Re-Connect button is displayed.
-
Case 1: When the Connect button is displayed:
-
When the Connect button is displayed if the Content Source authentication is successful. Along with the button, a message is displayed There are no crawl errors and the Content Source authentication is valid.
-

-
Fig. The Connect button is displayed on the Authentication tab.
-
Case 2: When the Re-connect button is displayed:
-
The Re-connect button is displayed when the authentication details change or the authentication fails for any reason.
-
In both cases, the Content Source connection must be authenticated again. To reauthenticate a Content Source, enter the authentication details, and click Re-Connect.
-
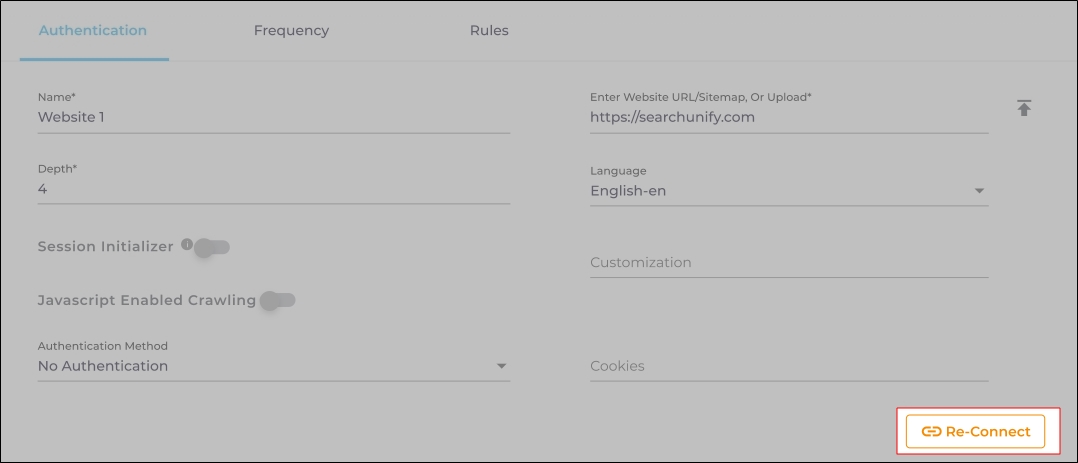
-
Fig. The Re-Connect button is displayed on the Authentication tab.
Set Up Crawl Frequency
The first crawl is always performed manually after configuring the content source. In the Choose a Date field, select a date to start the crawl; only data created after the selected date will be crawled*. For now, leave the frequency set to its default value, Never, and click Set.

Fig. The Frequency tab when "Frequency" is set to "Never".
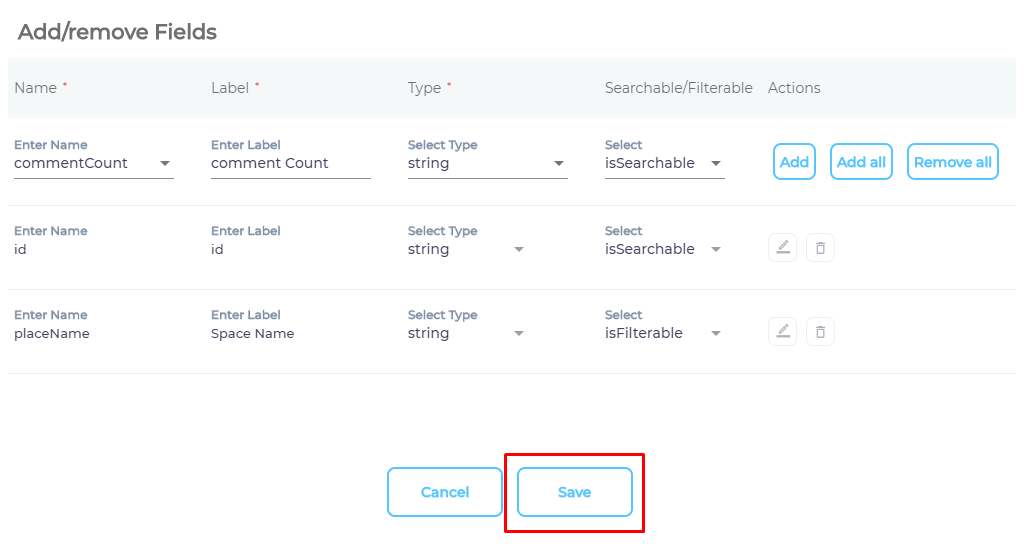
Select Types and Fields for Indexing
SearchUnify can index Confluence pages and blogs. You can choose to index them both, or select just one of them. You can further index all blog and page fields, or only a few of them.
- Click
 to select content fields.
to select content fields.
- Use the dropdown in the Name column to add content fields one at a time.

- OPTIONAL. SearchUnify assigns each field a label, type, and either an
isSearchableorisFilterabletag. The values don't require a change, but advanced users can edit them.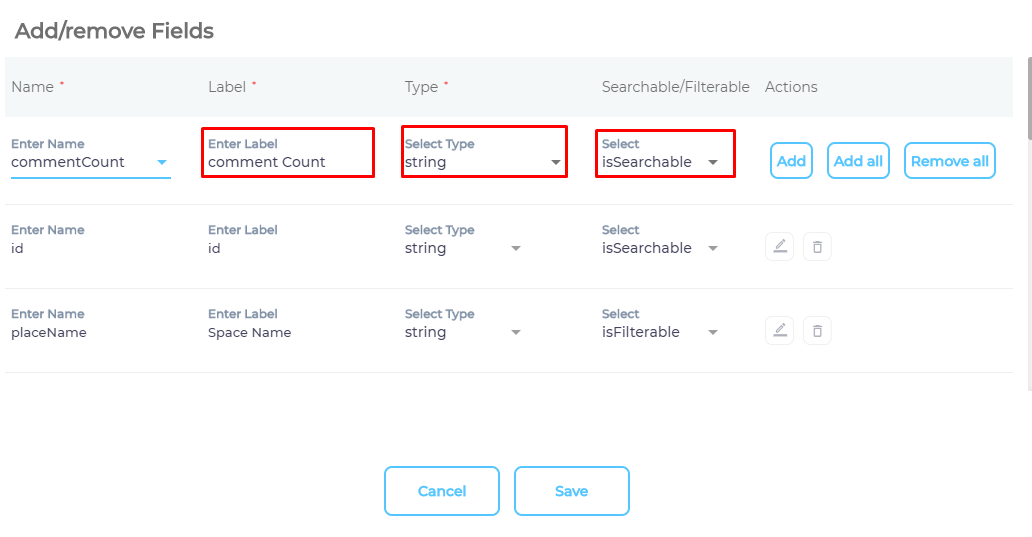
- Press Save.
- Repeat the steps 2-5 with the second content type.
- Navigate to By Place.

- Use the index to find your project and check enable for each one of it.

- Press Save.

You have successfully installed Confluence as a content source.
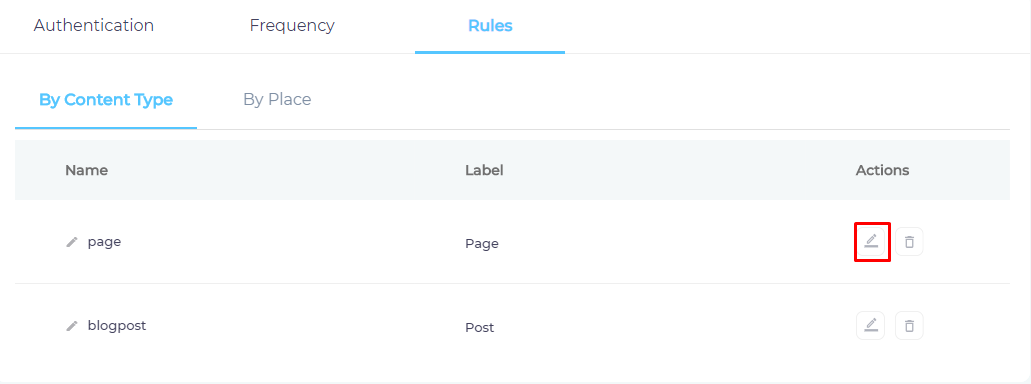
Find and Replace
Users on the Q2 '24 release or a later version will notice a new button next to each object on the Rules screen. It resembles a magnifying glass and is labeled "Find and Replace." You can use this feature to find and replace values in a single field or across all fields. The changes will occur in the search index and not in your content source.
Fig. The "Find and Replace" button on the Rules tab in the Actions column.
Find and Replace proves valuable in various scenarios. A common use case is when a product name is altered. Suppose your product name has changed from "SearchUnify" to "SUnify," and you wish for the search result titles to immediately reflect this change.
-
To make the change, click
 .
. -
Now, choose either "All" or a specific content source field from the "Enter Name" dropdown. When "All" is selected, any value in the "Find" column is replaced with the corresponding value in the "Replace" column across all content source fields. If a particular field is chosen, the old value is replaced with the new value solely within the selected field.
-
Enter the value to be replaced in the Find column and the new value in the Replace column. Both columns accept regular expressions.
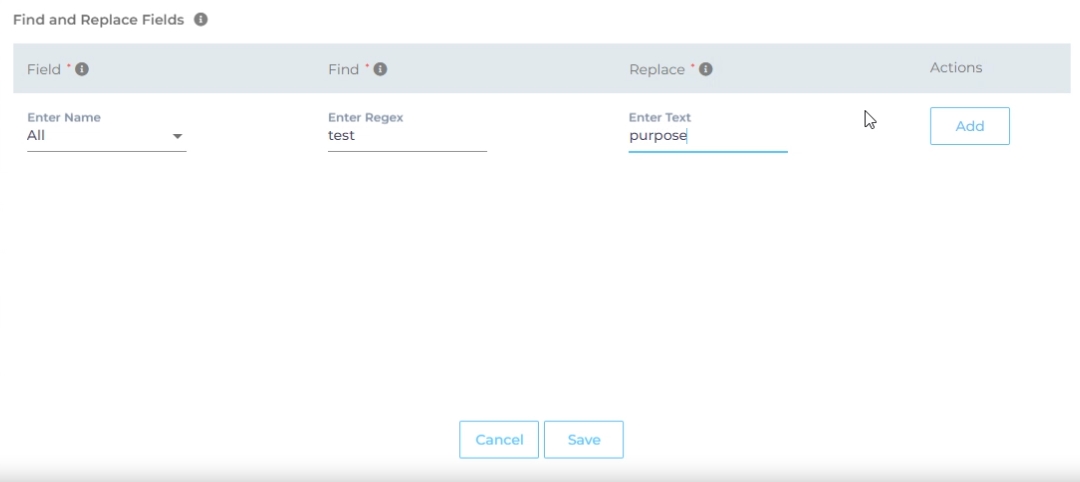
Fig. Snapshot of Find and Replace.
-
Click Add. You will see a warning if you are replacing a value in all fields.
-
Click Save to apply settings
-
Run a crawl for the updated values to reflect in the search results.
After the First Crawl
Return to the Content Sources screen and click ![]() in Actions. The number of indexed documents is updated after the crawl is complete. You can view crawl progress by clicking
in Actions. The number of indexed documents is updated after the crawl is complete. You can view crawl progress by clicking ![]() (View Crawl Logs) in Actions.
(View Crawl Logs) in Actions.
Once the first crawl is complete, click ![]() in Actions to open the content source for editing, and set a crawl frequency.
in Actions to open the content source for editing, and set a crawl frequency.
-
In Choose a Date, click
 to fire up a calendar and select a date. Only the data created or updated after the selected date is indexed.
to fire up a calendar and select a date. Only the data created or updated after the selected date is indexed.
-
The following options are available for the Frequency field:
-
When Never is selected, the content source is not crawled until an admin opts for a manual crawl on the Content Sources screen.
-
When Minutes is selected, a new dropdown appears where the admin can choose between three values: 15, 20, and 30. Picking 20 means that the content source crawling starts every 20 minutes.
-
When Hours is selected, a new dropdown is displayed where the admin can choose between eight values between 1, 2, 3, 4, 6, 8, 12, and 24. Selecting 8 initiates content crawling every 8 hours.
-
When Daily is selected, a new dropdown is displayed where the admin can pick a value between 0 and 23. If 15 is selected, the content source crawling starts at 3:00 p.m. (1500 hours) each day.
-
When Day of Week is selected, a new dropdown is displayed where the admin can pick a day of the week. If Tuesday is chosen, then content source crawling starts at 0000 hours on every Tuesday.
-
When Day of Month is selected, a new dropdown appears where the admin can select a value between 1 and 30. If 20 is chosen, then content source crawling starts on the 20th of each month.
It is recommended to pick a date between the 1st and 28th of the month. If 30 is chosen, then the crawler may throw an error in February. The error will be “Chosen date will not work for this month.”
-
When Yearly is selected, the content source crawling starts at midnight on 1 January each year.
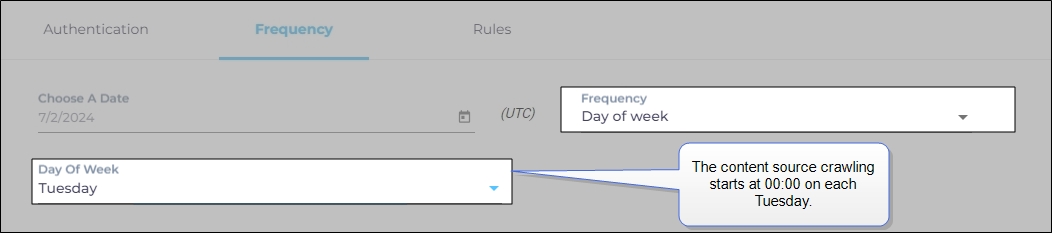
Fig. The content source crawling starts at 00:00 on each Tuesday.
-
- Click Set to save the crawl frequency settings.

-
Click Save.
Data Deletion and SU Index
All the data deleted from Confluence is removed from the SearchUnify index within 24 hours.