

Use Github As a Content Source
SearchUnify can crawl, index, and search your GitHub repositories. This article gets you started.
PERMISSIONS
SearchUnify ignores user permissions during searches. All indexed files can be searched by all users.
PREREQUISITES
You should have access to the repositories to be crawled.
Establish a Connection
-
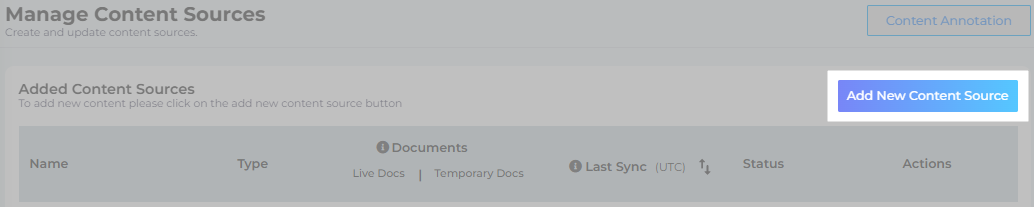
Navigate to Content Sources and click Add New Content Sources.
-
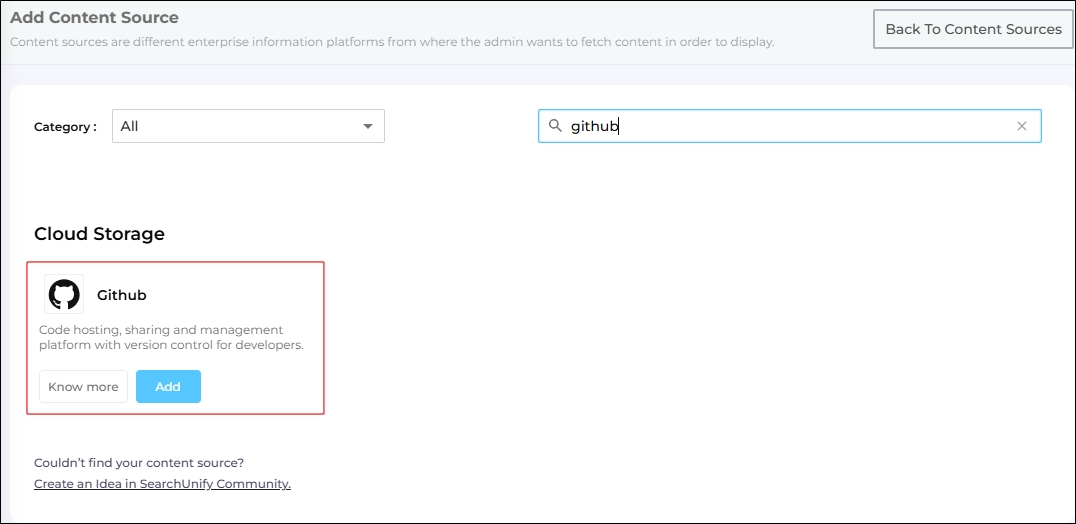
Find GitHub and click Add.
-
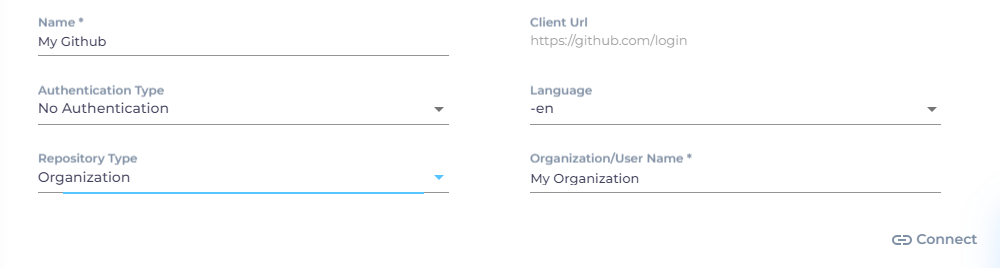
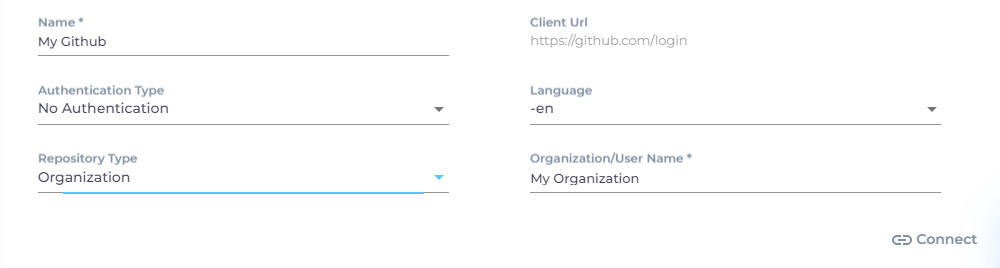
Under the Authentication tab, enter the required details:
-
Name: Provide a label for your content source.
-
Authentication Type: Select either No Authentication or OAuth from the dropdown.
Note. By default, only issues from public repositories are crawled. If you need to crawl private repositories, please contact SearchUnify support.
-
Language: Select the language used in the comments.
-
Repository Type: Choose the type of your GitHub account. Individual developers should select User, but for companies, the correct choice is Organization.
-
Organization/User Name: Enter your repository name.
-
After entering the required details, click Connect.
If a window pops up with the "Connection Successful" message, click Next. Once the connection is successfully established, you will be prompted to proceed to the next action—Set Up Crawl Frequency.
Re-Connect
An admin can edit a Content Source for multiple reasons, including:
-
To reauthenticate
-
To fix a crawl error
-
To change frequency
-
To add or remove an object or a field for crawling
When a Content Source is edited, either a Connect or a Re-Connect button is displayed.
-
Case 1: When the Connect button is displayed:
-
When the Connect button is displayed if the Content Source authentication is successful. Along with the button, a message is displayed There are no crawl errors and the Content Source authentication is valid.
-

-
Fig. The Connect button is displayed on the Authentication tab.
-
Case 2: When the Re-connect button is displayed:
-
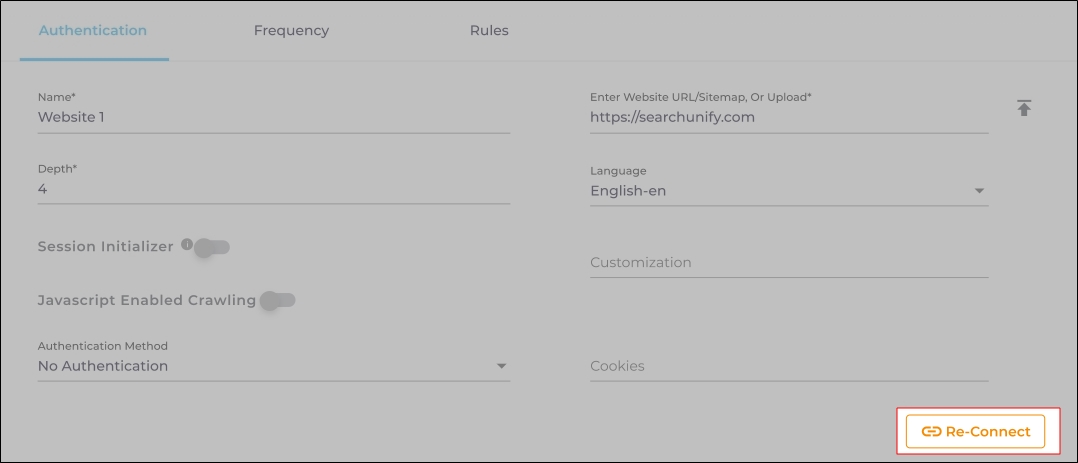
The Re-connect button is displayed when the authentication details change or the authentication fails for any reason.
-
In both cases, the Content Source connection must be authenticated again. To reauthenticate a Content Source, enter the authentication details, and click Re-Connect.
-
-
Fig. The Re-Connect button is displayed on the Authentication tab.
Set Up Crawl Frequency
The first crawl is always performed manually after configuring the content source. In the Choose a Date field, select a date to start the crawl; only data created after the selected date will be crawled*. For now, leave the frequency set to its default value, Never, and click Set.

Fig. The Frequency tab when "Frequency" is set to "Never".
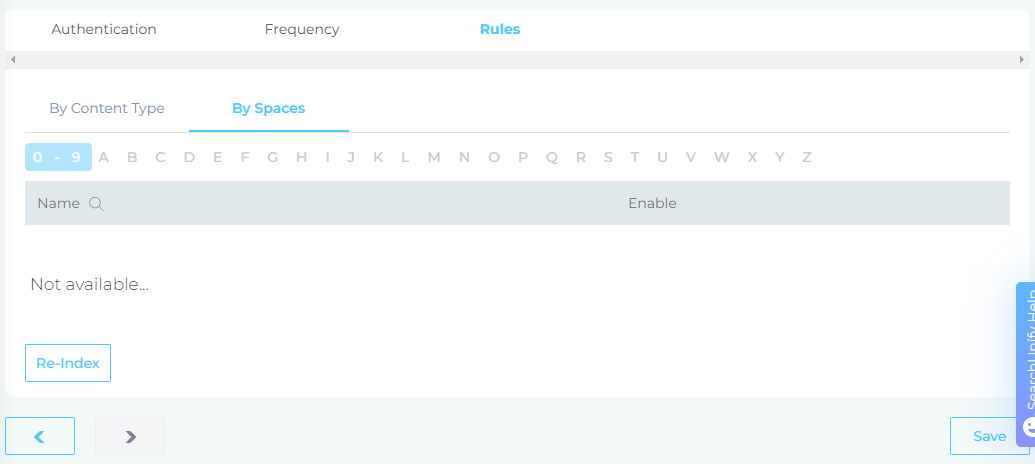
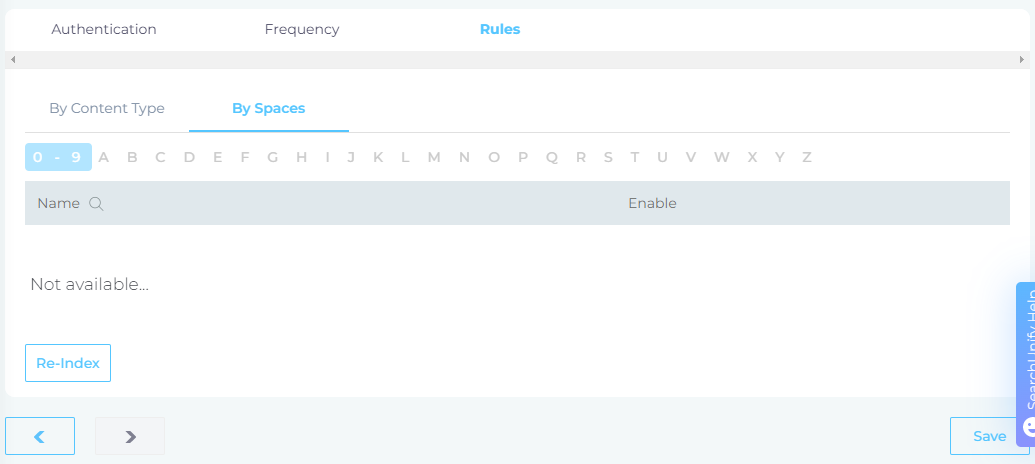
Select Fields and Repositories for Indexing
SearchUnify indexes three GitHub content types: issues, repositories, and pull requests. To configure these, navigate to the Rules tab and select the By Content Type subtab.
-
Click Edit in the Action column to view the pre-configured properties for a content type.
-
In the By Spaces section, use the index to search for and select the repositories for crawling. If no repositories are selected, all data stored in the supported content types from your GitHub repositories will be indexed.
Note. Both open and closed issues will be crawled in SearchUnify.
-
After making your selections, click Save to apply the changes.

NOTE. You can add or delete content fields, but it’s recommended that only Admin users make changes to these fields.
{kind=link}
{kind=link}
{kind=link}
You’ve successfully added GitHub as a content source in SearchUnify. To start indexing, perform a manual crawl.
Related
After the First Crawl
Return to the Content Sources screen and click ![]() in Actions. The number of indexed documents is updated after the crawl is complete. You can view crawl progress by clicking
in Actions. The number of indexed documents is updated after the crawl is complete. You can view crawl progress by clicking ![]() (View Crawl Logs) in Actions.
(View Crawl Logs) in Actions.
Once the first crawl is complete, click ![]() in Actions to open the content source for editing, and set a crawl frequency.
in Actions to open the content source for editing, and set a crawl frequency.
-
In Choose a Date, click
 to fire up a calendar and select a date. Only the data created or updated after the selected date is indexed.
to fire up a calendar and select a date. Only the data created or updated after the selected date is indexed.
-
The following options are available for the Frequency field:
-
When Never is selected, the content source is not crawled until an admin opts for a manual crawl on the Content Sources screen.
-
When Minutes is selected, a new dropdown appears where the admin can choose between three values: 15, 20, and 30. Picking 20 means that the content source crawling starts every 20 minutes.
-
When Hours is selected, a new dropdown is displayed where the admin can choose between eight values between 1, 2, 3, 4, 6, 8, 12, and 24. Selecting 8 initiates content crawling every 8 hours.
-
When Daily is selected, a new dropdown is displayed where the admin can pick a value between 0 and 23. If 15 is selected, the content source crawling starts at 3:00 p.m. (1500 hours) each day.
-
When Day of Week is selected, a new dropdown is displayed where the admin can pick a day of the week. If Tuesday is chosen, then content source crawling starts at 0000 hours on every Tuesday.
-
When Day of Month is selected, a new dropdown appears where the admin can select a value between 1 and 30. If 20 is chosen, then content source crawling starts on the 20th of each month.
It is recommended to pick a date between the 1st and 28th of the month. If 30 is chosen, then the crawler may throw an error in February. The error will be “Chosen date will not work for this month.”
-
When Yearly is selected, the content source crawling starts at midnight on 1 January each year.
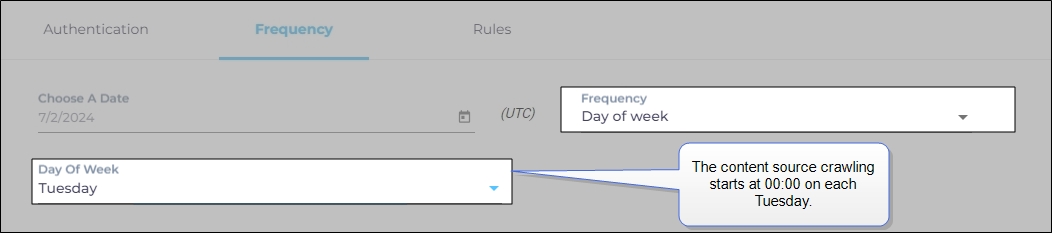
Fig. The content source crawling starts at 00:00 on each Tuesday.
-
- Click Set to save the crawl frequency settings.

-
Click Save.
Data Deletion and SU Index
A method to update the index in real time is to enable event subscriptions, which supplement existing crawls and synchronize data between your GitHub instance and SearchUnify in real time. Check out Enable Event Subscription in GitHub.