

How Documents Are Ranked in SearchUnify
Once the relevant documents have been found, the next challenge is to sort them. SearchUnify considers more than a dozen factors before returning results in any particular order to a user. They have all been touched upon in this article.
Preliminary Sorting
The processed search terms are matched with the index using Lucene's search and sort algorithm. The best matches are found based on the  formula, which has the following variables:
formula, which has the following variables:
- Term Frequency (
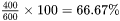 ). How often the query (
). How often the query (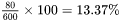 ) appears in a document (
) appears in a document (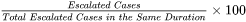 ).
). - Inverse Document Frequency (
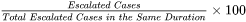 ). How often
). How often  appears across the index (
appears across the index ( ).
). - Coord. Number of terms in
 that are found in
that are found in  .
. - lengthNorm. Importance of
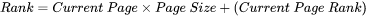 in
in 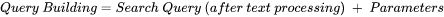 .
. - queryNorm. A variable to compare queries.
- Boost (Index). Boost at the time of indexing.
- Boost (Query). Boost at the time of query building.
Other Factors
Other factors in preliminary sorting that influence the search results are:
-
Operators. You can specify the default search operator to use when multiple keywords are present. In the default state, the operator is OR. When a user looks up intensive course, SearchUnify finds documents that contain the string intensive and course or either of those keywords.
-
Search Terms Proximity. Documents that contain the keywords the closest are ranked the highest. For a search query AI search, a document containing the phrase AI search is ranked higher than a document with the phrase AI and search. In the second document, AI and search are farther from each other than in the first document.
-
Exact Matches. Documents with exact query matches are ranked higher than documents that contain synonyms or lemmatized keywords. For a search query AI search, a document with the phrase AI search is ranked higher than another document with the phrase AI searching. Search, searches, searched, and searching are considered lemmatized forms of the query search*. The lemmatized matches have the least priority among exact matches and synonyms. The priority equation can be summed up as
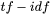 .
. -
Synonyms. Documents containing the synonyms of a query are prioritized over documents that neither contain the query nor its synonyms.
-
Lemmatized Keywords. Documents containing a inflected and conjugated search queries are prioritized over documents containing neither the query nor its lemmas. If you have search optimize search client, then a document containing optimizing search searches is preferred over those that contain neither optimize nor search client.
Advanced Sorting
The mapped documents are further ranked based on a proprietary algorithm. The variables in the algorithm include:
Relevance
Documents with the highest 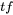 score are likely to end up near the top.
score are likely to end up near the top.
Activity History
Auto Tuning plays a big role here. If it's turned on, then user activity history is taken into account in deciding how the relevant documents will be ranked. The search results for a user might be different from another user. For details, check out How Auto Tuning Works and Its Features
Search Tuning Settings
.Three tuning configurations are available to SearchUnify admins:
Keyword Tuning.
Assign a document any rank between 1 and 10 for a query or a series. You cannot put two or more documents the same rank for a query; document-1 and document-2 cannot have the same rank for query. However, you can return a document on the same rank for one or multiple queries; document can have the same rank for query-1 and query-2. A setting in keyword tuning overrules all other factors and returns the document on its assigned rank. Check out Boost Documents for Specific Keywords
Content Source Tuning
.Unlike moving one document up or down at a time, admins can boost all the documents in a content source with content source tuning. Content boosting increases the default relevancy score of all documents. In the images, you can see what happens when a StackOverflow is boosted as a content source.
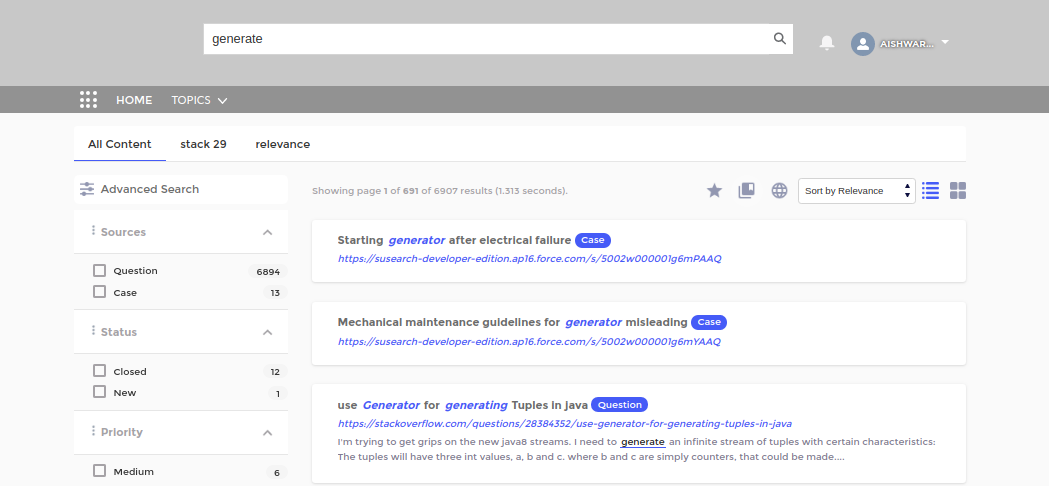
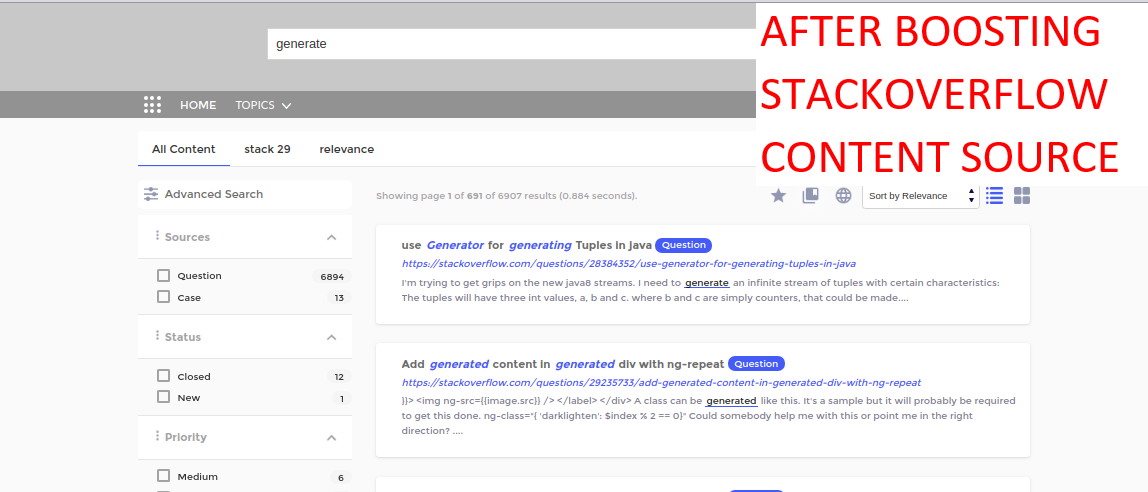
Boost All Documents in a Content Source
Field Tuning
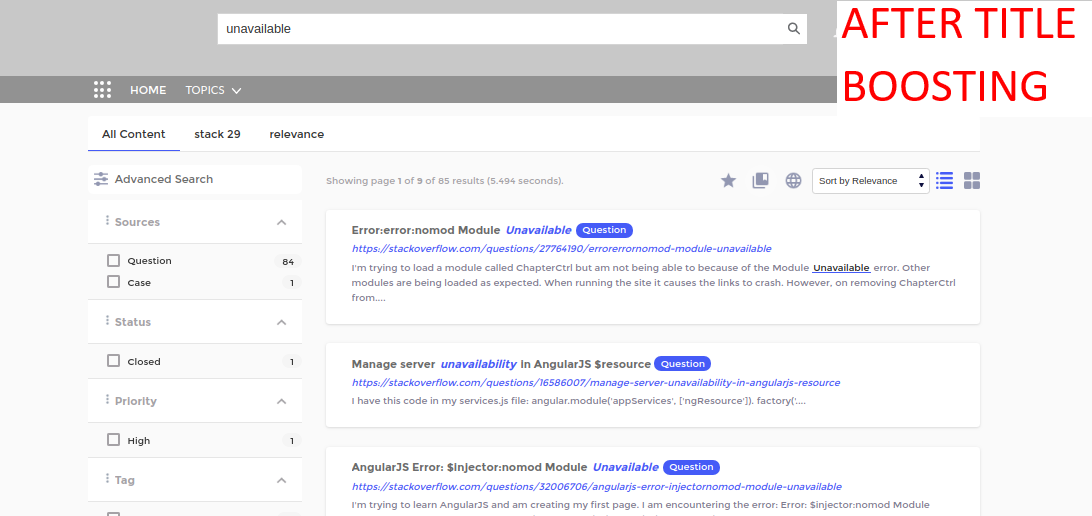
Supported fields are a document's title, its status, age, and popularity. An admin can alter the default emphasis on each field. For instance, a keyword match in the title can boost a document's relevancy score twice, thrice, or more. In the images, you can see the impact of title boosting for the keyword "unavailability." Custom Tuning: Boost most popular and latest documents

Publishing Date
Recent documents are preferred over older docs.
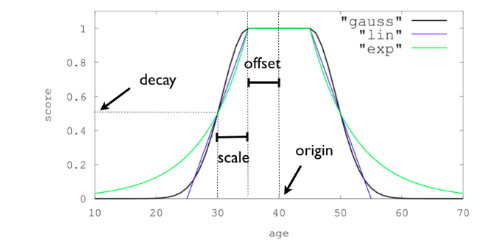
Parameters
- Offset. The period during which the score
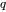 of a newly updated document doesn't change.
of a newly updated document doesn't change. - Scale. Once Offset has passed, begins to drop. It continues to drop for a time period, known as Scale.
- Decay [Rate]. The rate of drop of relevance score during Scale is controlled by Decay Rate,
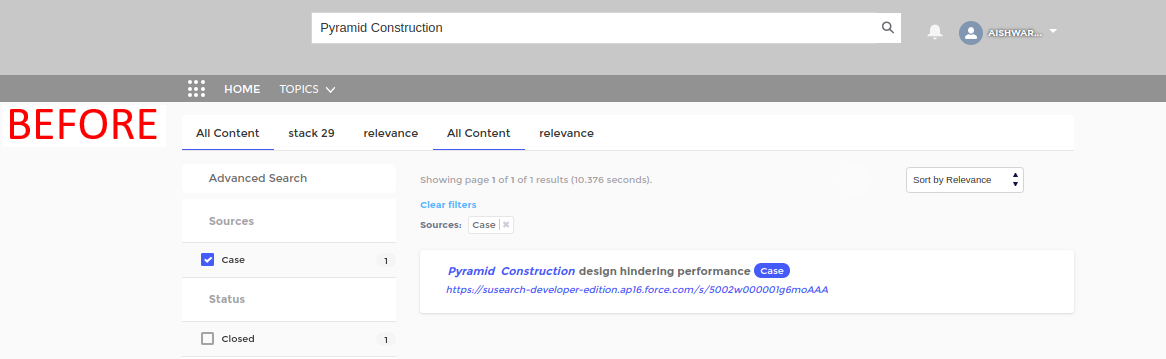
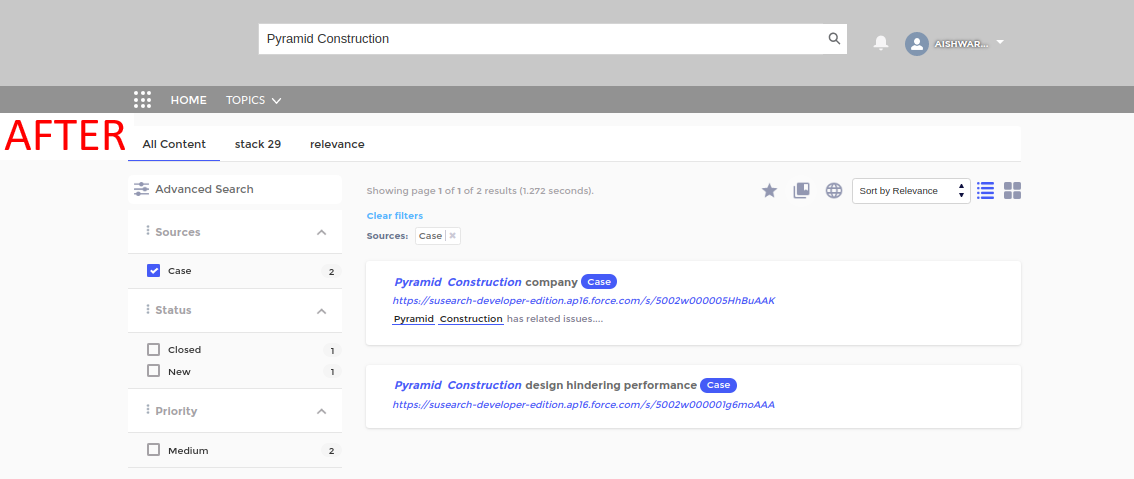
Example. A search for ‘pyramid construction’ before and after the creation of a new doc. The new doc is prioritized in the second image.
NOTE.
Some search queries activate SearchUnify's machine learning algorithms. As a result, a user receives up to 15 (instead of the usual 10) results. Machine learning algorithms fetch those extra results by applying facets and autocorrecting some search terms.
Related
- Previous article: How Queries Are Transformed During Search