

Relevance Architecture in SearchUnify
A search query goes through a four-stage process during the milliseconds a user enters the search query and get results: Text Processing -> Query Building -> Preliminary Sorting -> Advance Sorting.
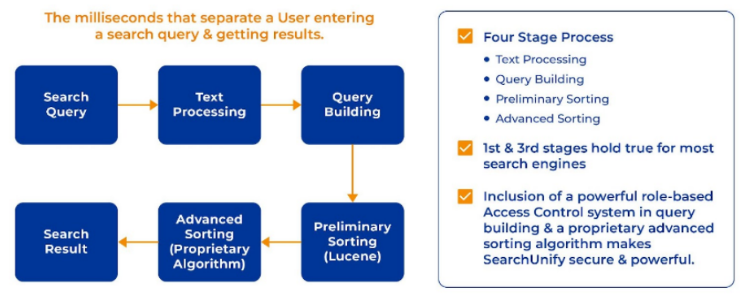
Once a search query is made, the first set of pipelines it goes through is Text processing.
1. Text processing
Query Cleaner or Classifier removes the least important stopwords or words from the search query. For example, the article [the] is usually removed from the query, [the martian times]. Further, the query is classified either as a question or as an information request. A query [what's the area of antarctic] is treated differently from the query [latest searchunify release notes]. The relevancy of search results depends on accurate classification.
Spell Check or Synonyms Engine can be trained on the indexed customer content and metadata to offer relevant corrections to search misspellings and suggest user-driven synonyms and abbreviations to improve search relevance over time. For example, based on customer content, the engine can identify that the queries [searchunify] and [su] are synonyms.
Related: Synonyms to Improve Search Experience.
2. Query Building
Intent Detector maps search queries against trained user intents. This helps deliver the most relevant search results configured against top intents by admins.
Related: Intent Tuning.
Facet Interpreter detects filters from the user's search query and applies them to refine search results. The use of filters helps users find the right content faster.
Auto-Boosting Models are trained on the basis of multiple attributes, such as user search and browsing behavior, click and view counts on articles, articles responsible for case deflection, and articles attached to solved cases. These models improve the ranking of relevant search results based on content reuse.
Behavior Modeling Data-driven query optimization uses conversions, facets use history, and keywords to create persona and custom weights for increased recall and precision. This persona drives features like Recommended Articles, which go beyond traditional search and serve content based on user journey signals.
3. Preliminary Sorting
Content Recommendations Engine generates recommendations for end users based on their interests and browsing history. This is the same engine that powers other SearchUnify applications, such as Agent Helper, Escalation Predictor, SUVA, and Community Helper.
4. Advanced Sorting
Advanced sorting is powered by SearchUnify's proprietary algorithms. The approach to relevance can be divided into three segments:
Retriever
Through Named Entity Recognition (NER), Retriever tries to understand queries and the entities present in it to fetch a set of relevant candidate documents. The NER models extract entities from search queries and filter the results according to labels mapped with that entity. The user doesn't have to select facets to define the scope of search. The facets are detected from the query.
For example, for a query [i want to book a ticket to california], the model detects the entity [california], labels it as a Place, and filters the results automatically only for "California".
This approach reduces user effort in selecting navigational facets and filters while, at the same time, providing better quality search outcomes.
Approximate Nearest Neighbor (ANN)
This is a technique in which, rather than searching all candidate documents in an index, ANN searches only on those documents which are approximately similar to the query. ANN works by dividing the documents into clusters or hyperplanes.
When a user enters a query, an ANN first searches the relevant cluster or hyperplane and then performs a query search in that cluster or hyperplane. SearchUnify uses smart indexing or ANN for faster document and query retrieval.
Semantic Reranking
Semantic Reranking goes beyond simple occurrence-based token matches. A word is defined by the company it keeps.
For example, a carrot is to an apple is the same as vegetables are to fruit. That same query can be asked in different ways, contexts and with different intents and vocabularies.
SearchUnify uses semantic reranking by generating contextual embeddings for queries and documents. These embeddings are used in smart indexing, thereby helping deliver more relevant search results for end users, faster.

It generates recommendations for end users by not only matching the tokens of the query and the documents, but also reranking the documents based upon the context present in the individual user's search query.
For example, for a query [i want to make a deposit] the system first finds documents with the token "Deposit" . Then it reranks the documents based on the context in which the user is searching, which in the current case is: The user wants to deposit the money into their account. After reranking, the end user gets a recommended article of how to deposit the money into a bank account.
Serving Results
SearchUnify doesn't just present users with the most relevant content in a search results page. It connects users with the most relevant parts of the content directly within the search results. The Rich Snippets engine, powered by SearchUnify’s proprietary NLU algorithms, parses the most relevant content in the search results (including rich media) and presents them to users as step-by-step resolutions or direct answers.
Related. Enable Rich Snippets and Rich Cards and Structure Content for Rich Snippets: Tips for Writers
Rich Snippets try to figure out the most relevant part of the content and on runtime they are able to identify generated snippets that are most relevant to offering an answer to the user’s search query.
