

Mamba '23 Release Notes
SearchUnify is constantly evolving and adding new features. The sheer number of enhancements in the platform since the previous release has been immense. Mamba ‘23 promises superior user experience for admins and search users.
Admins set up search client Ecosystems to track 360° customer journeys, add new functions to search client pages by adding custom CSS and JavaScript in Imperium Editor, and monitor the impact of rich snippets and content annotation in ML Workbench. Each of these features is new.
On their part, search users can get keyword and intent tuned results irrespective of other settings and offer feedback in four different ways.
These and all other features which make Mamba ‘23 great, have been covered in this edition of release notes.
Mamba ‘23 starts rolling out to customers for sandbox deployment towards the end of November 2022, and production deployment begins in the beginning of December 2022. All updates-related queries can be directed to support@searchunify.com.
Core Platform
A major update in the core platform is the launch of ML Workbench, where admins can see how machine learning works for rich text and content annotation. In content sources, three new connectors have been introduced: Monday,com. Guru, and Knowledge Owl. As for search clients, programmers are going to love the Imperium Editor that offers powerful customization capabilities.
Content Sources
The highlights are the release of crawlers for three new platforms and introduction of synonyms in Content Annotation.
Real-Time Indexing Data During Crawls
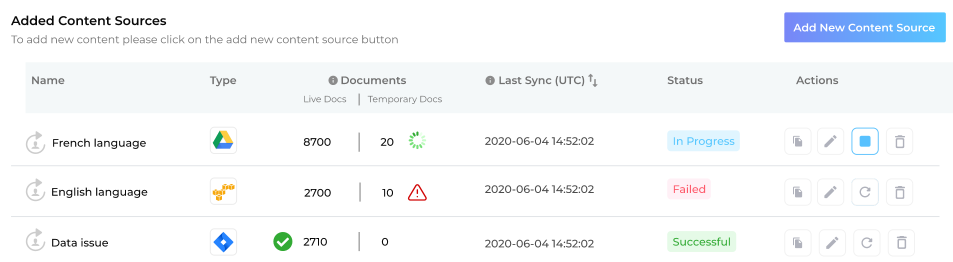
Total Documents has a new name,
Documents, and it comes with a counter
now. Admins can learn in real time the number of
indexed files while a manual crawl is underway.
A green progress circle ( )
next to a count in Temporary Docs means
that the crawl is progressing successfully. A
warning sign (
)
next to a count in Temporary Docs means
that the crawl is progressing successfully. A
warning sign ( )
suggests a crawl gone stuck.
)
suggests a crawl gone stuck.
Temporary Docs has been introduced so as not to impact search on a production instance while a manual crawl is underway. Earlier, end-users couldn’t search during the duration of the crawl. It is no longer the case. Temporary Docs works when a manual crawl is active on five content sources: Website, Higher Logic, Dropbox, Docebo, and Vidyard. All frequency crawls and manual crawls for other content sources are captured in Live Docs.
As for the old column with data on searchable docs, it has moved to Live Docs.
Link: Documents: View Searchable Docs
Searchable Files Count for Each Salesforce Object
Find out the number of documents that have been crawled from each Salesforce object. The document count for each Salesforce object is listed in Documents under the Rules tab.

Link: Crawl Just One Object in Salesforce
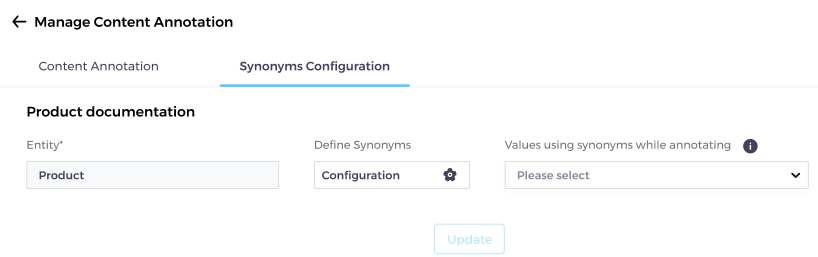
Accurate Data Annotation with Synonyms
Admins have been using entities in Content Annotation for a few months now. Mamba ‘23 gives them more power. Instead of defining “SearchUnify” and “SU” as two separate entities, admins can use synonyms. This leads to conceptually cleaner annotations because instead of tagging 10 posts by “SearchUnify'' and 7 by “SU”, admins can tag all 17 by “SearchUnify.”
Link: Synonyms Configuration
New Content Sources: GetGuru, Knowledge Owl, and Monday
New crawlers can index data from GetGuru, Knowledge Owl, and Monday. GetGuru and Knowledge Owl are popular platforms for companies seeking to create collaborative knowledge bases. Monday is a project management tool with support for CRM, resource management, and practically anything a business needs.
Link: Use GetGuru as a Content Source, Use KnowledgeOwl as a Content Source, and Use Monday as a Content Source
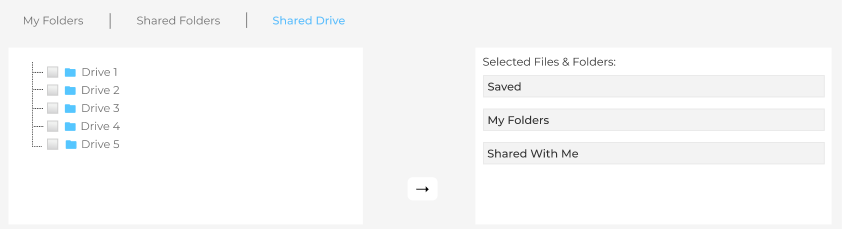
Search for Shared Google Drives on Your Intranet
The Google Drive crawler can index content from the drives shared with you. To start, check at least one Shared Drive in Rules > By Folders > Shared Drive.
Link: Use Google Drive As a Content Source
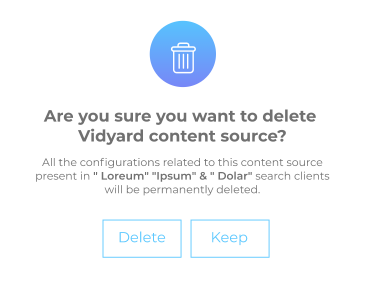
More Informative Infobox on Content Source Deletion
Each time you try to delete a content source, a warning box lists the search clients linked with it. You can review the list to make an informed decision.
Link: Delete a Content Source
Search Clients
The highlights include the introduction of ecosystems, which offers the capability to track 360° customer journey across multiple platforms and analytics and the Imperium Editor where admins can customize Imperium search clients.
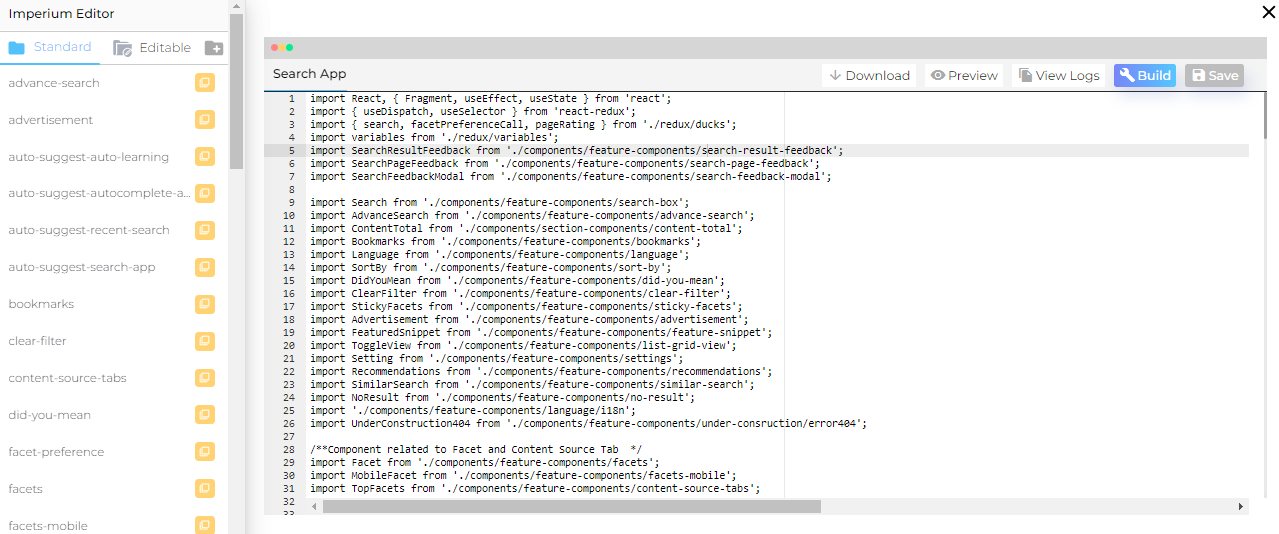
New Search Client Editor for Imperium Search Clients
Tweak the appearance and functionality of your search client pages with a built-in Imperium Editor. The editor lets admins upload their own CSS in Styles and customize ReactJS search client components. A Preview button gives them the freedom to experiment without impacting search on production.
Link: Deliver Faster Search on a Configurable Search Client with Imperium
360° Customer Journey View with Ecosystems
The entire journey of a user moving from a Website knowledge base to Salesforce to log a ticket can now be visualized in a unique Ecosystem session. Many admins have their knowledge bases and ticketing systems on separate platforms. With Ecosystem, admins don’t lose track of users when they jump from a platform to another.

Link: Search Client Ecosystem to view 360° Customer Journey
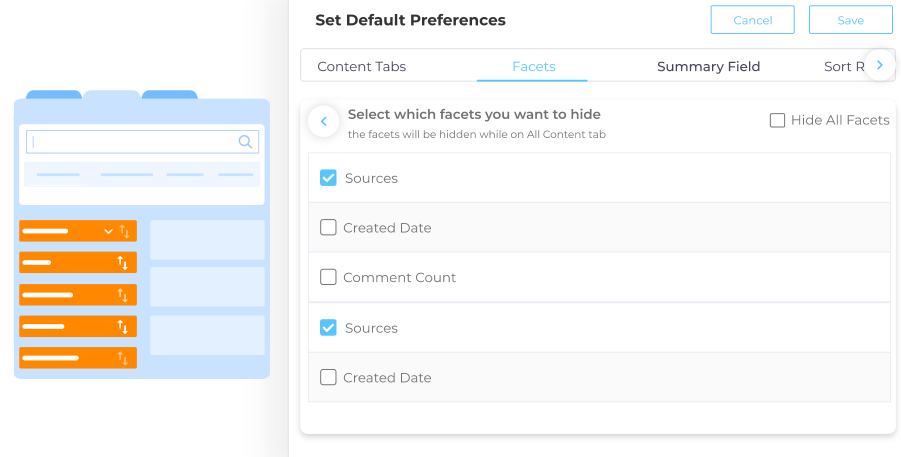
Hide Filters to Reduce Clutter on Search Pages
Too much of a good thing can be unpleasant. This advice can be applied to search filters. Results on the right and an endless array of search filters on the left can clutter search pages, and make navigation difficult. To offer a cleaner interface, admins can now hide one or more filters from the search results page when their users are on the All Content tab.
Link: Rearrange or Hide Facets on Search Clients
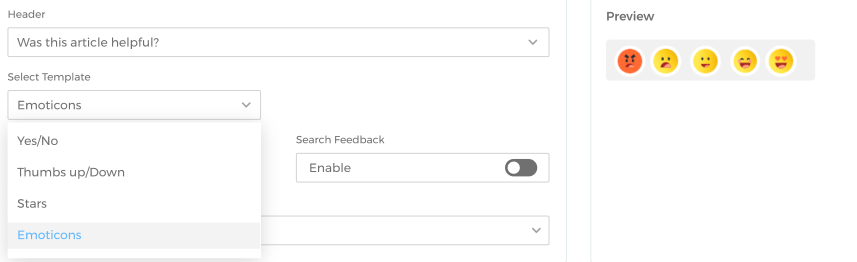
User Feedback on Content with Emoticons and Stars
Admins have two new rating scales to use on websites and search result pages. The first lets readers give a star rating and the second lets them pick an emoji, from terrible to amazing. Setting up a rating scale is as easy as choosing a template. The feedback is gathered in the newly introduced Content Experience Feedback report. (See: Search Analytics in Mamba ‘23 Release Notes)
Link: Content and Search Experience
Recommended Articles
It has been introduced again in Search Clients > Edit > Configurations. Turning it on offers search users most popular articles related to their query right after the search results. It’s now a widget.
Link: Basic Search Client Configurations
Search Analytics
Search Analytics has expanded with a new report.
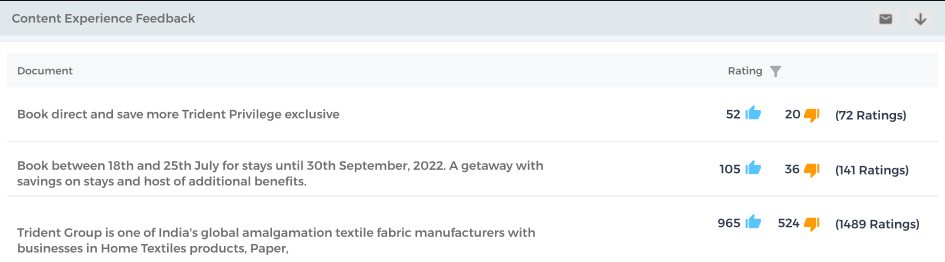
New Filters and Sort Options in Content Experience Feedback
One of the goals of setting up a feedback system is to find out which content users perceive as helpful and which content repels users. New filters in Content Experience Feedback make the task easier. Admins can sort documents, where readers give feedback, by Thumbs Up count, Likes, and Dislikes. If the rating scale in use is Stars or Emojis, then admins have another filter to pull up documents with a star rating or emoji.
Link: Content Experience Feedback
Search Tuning
Search users can overrule all search settings, including filters, with a new checkbox that returns intent- and keyword-boosted results. Admins can find popular documents that aren’t on page one.
Force Apply Keyword and Intent Tuning
In the default set-up using filters and advanced search queries impacts keyword and intent tuning. A result slated for rank two may or may not turn up on its position if an end-user applies a filter. Admins can now give search users a choice. Check Bypass All Filters in Manual > Intent and/or Manual > Keyword. When Bypass All Filters is checked, a checkbox appears on search clients which end-users can tick to force apply keyword and intent tuning.
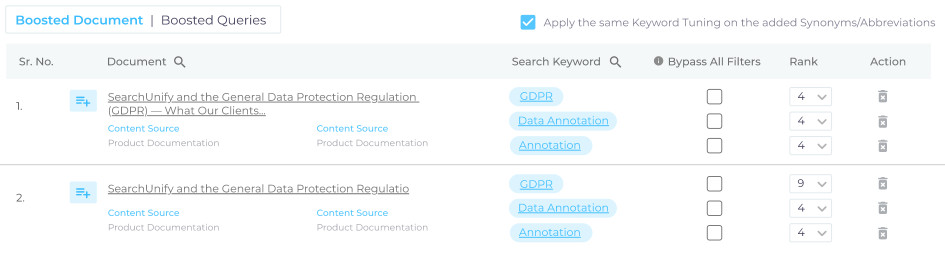
Link: Intent Tuning and Boost Documents for Specific Keywords
Report to Boost Popular Results Buried on Page Two and Beyond
With a revamped report in Keyword Tuning, admins can find the pairs of top keywords and most-clicked documents not on page one. The latter function makes the report different from High Conversion Not on Page One, which doesn’t offer the boost capability. The keywords for which the results ought to be boosted are highlighted right inside the report.
Link: Boost Documents for Specific Keywords
Auto Tuning
It now calculates relevancy based on the click behavior of all users on a search client. This update leads to more accurate results.
Link: How Auto Tuning Works and Its Features
ML Workbench
ML Workbench is a new feature. It offers admins the tools to visualize ML-powered features and a playground to test Rich Snippets and Content Annotation capabilities.
New Machine Learning Tool: ML Workbench
Admins can test how ML-powered features work in SearchUnify. The feature currently works for rich snippets and content annotation and its range will expand in future releases.
To find how it works, enter the URL of a webpage or its HTML code in Rich Snippets. The system will extract the snippets. Observing the process, you can learn how the snippets are generated. As to content annotation, insert a text and ML Workbench returns entities along with values from the text.
Observing how it’s done helps you optimize your content for SearchUnify.
Link: Machine Learning (ML) Workbench
API
The big change in API is the replacement of the “API Logs” tab with “API Consumption” and the introduction of two reports in the new tab.
Two New Reports to Monitor API Consumption
Two new reports in API Consumption (previously API Logs) provide data on API usage. The reports are Current Quota Consumption and API Consumption for Previous Instances. The first report displays API usage per minute, hour, day, and month. In the second report, you can find API usage for each session.
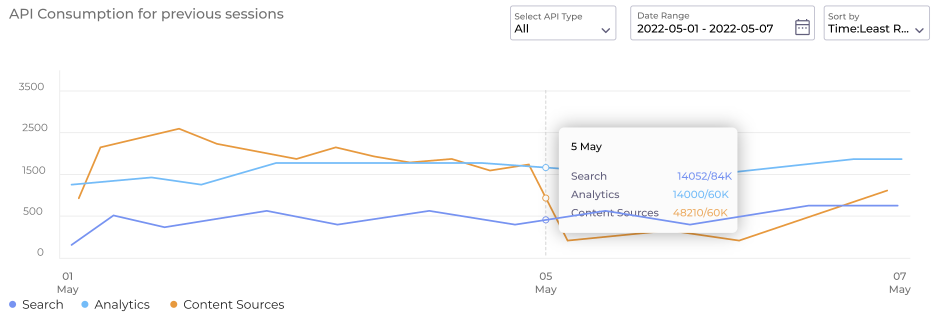
Link: View API Consumption Data
Applications
Two updates have been introduced in Agent Helper and the factors considered for predicting escalations in Escalation Predictor have been updated. Now case sentiment and the last-edit-time play an important role.
Agent Helper
The most conspicuous change is the relocation of Agent Helper from Search Clients to Apps. Another big change is the introduction of Case Sentiment Terminology in Overview.
Agent Helper Is Now in Apps
The app used to be in Search Clients > Edit > Agent Helper. But it has now moved to Apps. To configure Agent Helper, go to Apps and open the app.
Link: Agent Helper for Support Agents
Case Sentiment Terminologies Added to Overview
Overview in Agent Helper for Salesforce (LWC) now has a section named Case Sentiment Terminologies, which highlights the keywords used to figure out user sentiment for a case.
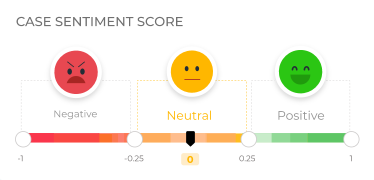
Link: Using Agent Helper in Salesforce
Escalation Predictor
Quick diagnosis, when services are down, allows admins to fix Escalation Predictor faster.
Alert on the Expiry of Access and Refresh Tokens
A message pops up on the Input Data screen when either access and/or refresh token has expired. The message takes away an element of mystery as to why the system is down.
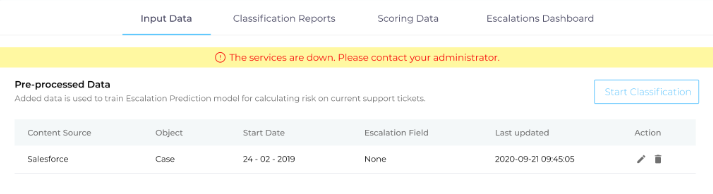
Link: Set up Escalation Predictor to Preempt Customer Escalations
Bug Fixes and Enhancements
-
Box (Content Source). To prevent deleted files from Box showing up in search results, webhooks have been implemented. Now each time a file is removed from Box, it’s deleted from the search index as well. Comments are crawled immediately.
-
Dropbox (Content Source). The crawler supports business accounts now. To crawl team data, a business account admin can insert their Dropbox client ID, client secret, and account type during authorization. Instead of all the files in paper, only the files with the extension .paper are crawled.
-
Escalation Predictor. Case prediction model updates over time. As new cases pour in, the model updates.
-
Escalation Predictor. Differences between the reports in SearchUnify and Salesforce have been eliminated. You can now have a seamless experience consulting reports on either platform.
-
HigherLogic (Content Source). Search users can use the Community filter to find Events. To turn it on, connect with the SearchUnify team. Once you have subscribed to community events, other events will not be indexed.
-
GitHub (Content Source). Admins can crawl private repositories and issues.
-
Jira (Content Source). Comments can now be crawled on the drive after adding a new field.
-
Khoros (Content Source). Article status for blogs can now be indexed in the state field. Spam is deleted each hour.
-
MindTouch (Content Source). A new authentication type, API, has been introduced. Using Groups and Direct Mail, admins can fine tune permissions on the page level.
-
Salesforce (Content Source). Two field fields can now be indexed in caseObject, caseFeed and UserOrGroupId.
-
ServiceNow (Content Source). Frequency crawl has been updated so that only the data added after lastSyncDate is inserted into the search index.
-
Similar Searches is more accurate in its suggestions.
-
Slack (Content Source). New formats are now supported: PDF, DOC, DOCX, PPT, XLS, XLSX, and CSV. Admins can crawl threads and attachments
-
Vimeo (Content Source). Admins can now crawl subtitles. If you have already set up Vimeo, edit the content source and add a new field, subtitle, in Rules.
New Products
KCS Enabler and Virtual Agent are standalone products now with new names. You can find their release notes on Knowbler 2022 Release Notes and SUVA 2022 Release Notes.